365
Google cosplay is not business-critical
(programming.dev)
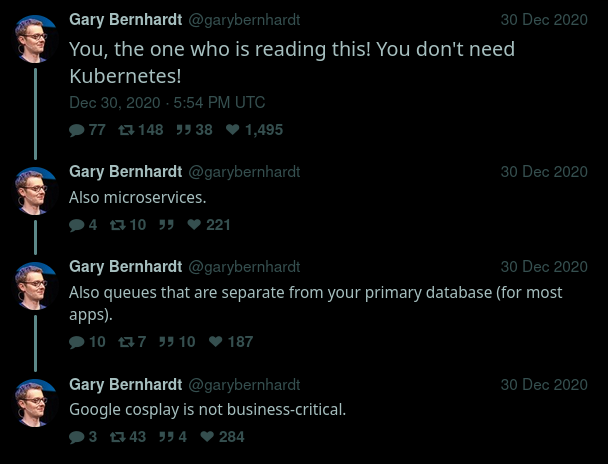
Transcription: a Twitter thread from Gary Bernhardt.
- You, the one who is reading this! You don't need Kubernetes!
- Also microservices.
- Also queues that are separate from your primary database (for most apps).
- Google cosplay is not business-critical.
Source: https://twitter.com/garybernhardt/status/1344341213575483399