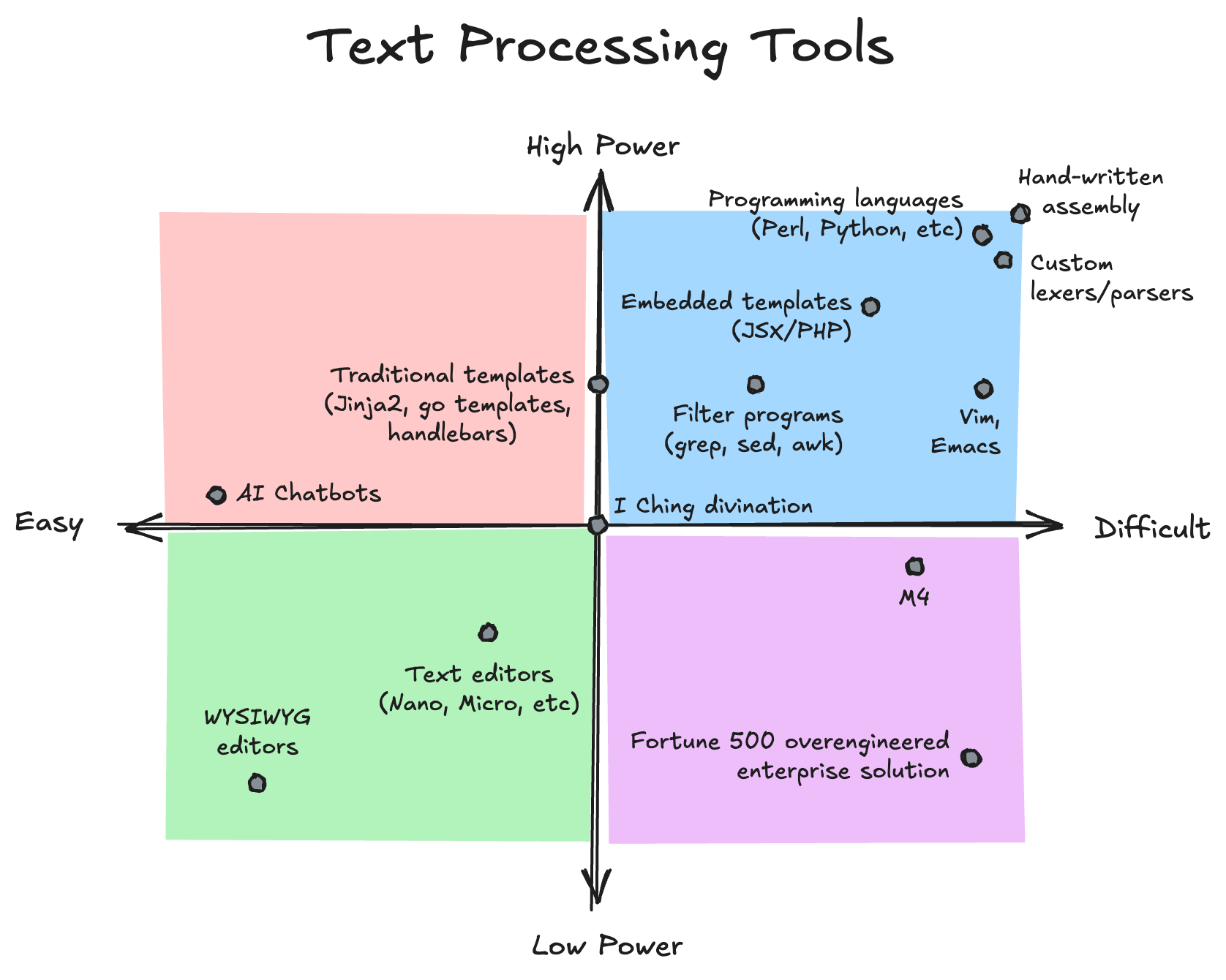
2
Makefiles For Threesomes
(sebastiancarlos.com)
Yes, I’ll host the source code on GitHub. I could consider mirroring it on Sourcehut if there’s enough interest, but I prefer the PR and Issues workflow on GitHub for collaboration. Plus, more people tend to have GitHub accounts than GitLab or Sourcehut, which makes it easier for contributors.
I get the concern about Microsoft, and while I’m not a fan of the company, GitHub has advantages that are hard to beat, especially for community reach. As for OpenAI potentially using the code, personally I don’t mind if my own code gets used for AI training. I’ll be using an MIT license, in case you're curious. Everyone is free to mirror it anywhere.
It's Exclidraw (dark mode)
Totally understand your perspective, and I’m not here to push back against it. You’ve got a valid point.
I’ll just add that there are already commercial tools that do similar things to what I’m building. It’s interesting to consider how perceptions might shift if a tool were released by a company rather than a solo developer. Sometimes the context influences how a tool is interpreted, even if the underlying functionality remains the same. For what it’s worth, I have no commercial intent behind this.
Exactly! My tool is designed to work with existing time-tracking tools by processing their output. You can think of it as a post-processor that helps clean up and format the data.
Since there are already plenty of time-tracking tools out there (both CLI and GUI), I wanted something that could act as a flexible add-on for them.
Hey, thanks for the comment. I get that it might be used for something shady, but that’s not the intention. The primary goal is to clean up raw time-tracking data into a format that’s easy to present to clients or supervisors, especially for contexts when small gaps or irregularities should be absent.
I imagine most professionals aren’t expected to account for every single minute of their workday. For example, if you’re switching tasks or taking short breaks. It’s more about reporting general productivity or overall progression of tasks, not trying to inflate hours.
Anyone aiming for 'time fraud' could probably find easier methods. My focus is to make life easier for people who already track their work but want cleaner, more digestible reports.
Appreciate the feedback though, helps me make sure the use case is clear! :)
It's almost done (it would take one or two weeks to clean it up for FOSS release). It's a CLI tool. It works great for my use case, but I'm wondering if there's any interest in a tool like this.
Say you have a simple time-tracking tool that tracks what you do daily. The only problem is that there are gaps and whatnot, which might not look nice if you need to send it to someone else. This tool fixes pretty much all of that.
Main format is a JSON with a "description", and either "duration" or a "start"/"end" pair. It supports the Timewarrior format out of the box (CLI Time tracking tool).

And what's your workflow when working with lots of files in projects with fish?
Unlike a password manager that just logs you in, Beachpatrol can run any automation task, like checking your email, downloading files, or filling out forms. You have to create Playwright scripts for these tasks and run them from a shell command. There is an example script already in the commands folder, which you can run with the command beackmsg smoke-test. The sky is the limit, basically.
Cool project! I'll check it out.
Regarding userscripting, from the F.A.Q.:
Why use an external automation tool (Playwright) instead of a browser extension?
While Beachpatrol allows to control the browser from both the OS and from a browser extension, our priority was the OS. Therefore, something like Playwright was the natural choice.
Furthermore, while controlling the browser from an extensions is possible, Manifest v3 removed the ability to execute third-party strings of code. Popular automation extensions like Greasemonkey and Tampermonkey could also be affected by Manifest v3. The alternative is to embed the code into the extension, but that would requires re-bundling the extensions after every change. Other tricks do exist to make this approach work, and there is some hope for future Manifest v3 solutions, but this path is certainly tricky.
It is more likely that Selenium and related tools will continue to work in the foreseeable future given the business demand for traditional browser testing.
Makes sense and you're probably right, but I'll tell you why I didn't do it that way:
Tbh these scripts are for my personal use, written in the way that makes sense for me. I only open sourced it as a joke an as an example of how reinventing your own wheel is not that hard sometimes, and comes with the benefit of doing just what you need it to do.
Actually I was thinking of adding a sysget fallback, as I might need to do some debian/fedora hacking soon.